SFB 501
Literaturverwaltung - How to
Nachfolgend ein Leitfaden, wie die automatisierte Literaturverwaltung des SFB
Web-Servers funktioniert und wie man sie benutzt.
Allgemeines
Um größtmögliche Aktualität der auf dem SFB-Webserver zur Verfügung gestellten
Literaturlisten (betrifft Veröffentlichungen des SFB bzw. der SFB-Teilprojekte)
sicherzustellen und gleichzeitig zusätzlichen Verwaltungsaufwand für die einzelnen
Teilprojekte minimal zu halten, wurde entschieden, die Verwaltung der Literaturlisten zu
automatisieren. Das vom SFB-Vorstand beschlossene Konzept sieht vor, daß Literaturlisten
dezentral von den jeweiligen Teilprojekten verwaltet werden und ein zentraler Index aller
Veröffentlichungen auf Basis der dezentralen Daten automatisch erstellt wird.
Die dezentralen Literaturlisten sind dazu auf öffentlich zugänglichen Webseiten
bereitzustellen, die mittels spezifischer Tags (HTML-konformer Markierungen) so
aufzubereiten sind, daß ein auf dem SFB-Webserver laufendes Skript die relevanten
Einträge auf diesen Seiten erkennen und die entsprechenden Informationen extrahieren
kann. Typischerweise können hierzu die auf den Webseiten der meisten Teilprojekte ohnehin
bereits existierenden Literaturlisten verwendet werden, die lediglich um die
entsprechenden Markierungen zu ergänzen sind.
Die URLs der Literaturseiten müssen beim Literaturverwaltungssystem registriert werden
- zum Zweck der Authentisierung ist hierzu ist ein entsprechender Account erforderlich,
der bei mir erhältlich ist. Registrierte
Benutzer können dann projektspezifisch URLs eintragen, löschen und das
Generierungsskript starten.
Benutzung
|
| |
Jeder, der URLs registrieren oder deregistrieren möchte, oder die
Generierung des zentralen Literaturverzeichnisses starten möchte, benötigt einen
Account. Accounts für die Web-Beauftragten der Teilprojekte gibt's bei mir - einfach eine email mit dem
Wunsch-Paßwort schicken.
|
|
|
Unter Results -> Publications -> Publications Management
gibt's das Anmeldeformular. Hier sind das Teilprojekt zu wählen, für welches die
Änderungen vorgenommen werden sollen, und Name und Paßwort anzugeben. Dann auf
"Enter" drücken.
|
3. URL registrieren
|
|
Auf das Einloggen folgt ein Dialog, der die derzeit für das gewählte
Teilprojekt registrierten URLs auflistet, und es erlaubt, eine neue URL zu registrieren,
eine auszuwählende URL zu deregistrieren und das Generierungsskript zu starten.
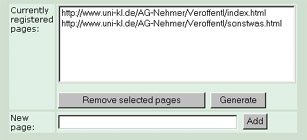
Um eine neue URL zu registrieren, muß diese am unteren Dialog-Rand unter "New
page:" eingegeben werden - anschließend "Add" drücken. Nach einem kurzen
Augenblick (je nach Netzanbindung ca. 1 Sekunde) erscheint die eingegebene URL in der
Auflistung.
ACHTUNG: Die URL muß vollständig
eingegeben werden, d.h. in der Form http://host/path/file.
URLs, die nicht mit http:// beginnen, werden bei einem Generierungslauf ignoriert!
|
4. URL deregistrieren
|
|
Um eine unter "Currently registered pages:" aufgelistete URL zu
deregistrieren, wird diese angewählt, und dann auf "Remove selected page"
gedrückt. Es kann derzeit immer nur eine URL gleichzeitig gelöscht werden - sollen
mehrere gelöscht werden, so ist dieser Vorgang für jede URL zu wiederholen. Einen kurzen
Augenblick (ca. 1-2 Sekunden) nach Drücken des "Remove selected page"-Knopfes
erscheint die URL-Liste aktualisiert.
|
|
|
Mit einem Klick auf den Knopf "Generate" wird das
Generierungsskript gestartet. ACHTUNG:
dieses Skript hat eine ganze Menge zu tun und braucht dafür auch u.U. eine ganze Menge
Zeit (bis in den zweistelligen Sekundenbereich!). Solange das Skript läuft, können keine
weiteren Eingaben gemacht werden - also nicht wundern, wenn's ein wenig dauert...
Hat ein anderer Benutzer kurz zuvor bereits eine Generierung angestoßen, und
ist dieser Vorgang noch nicht abgeschlossen, bekommt man eine Meldung, daß
der Generator gerade beschäftigt ist. Man muß dann kurz warten und
es nochmal probieren.
Ist die Generierung abgeschlossen, wird automatisch ein Report ("Processing
Results") angezeigt, in dem das Generierungsskript seine Tätigkeiten dokumentiert.
Dieser Report sollte nun genau überprüft werden - insbesondere ist auf rote ERROR-Zeilen zu achten: hier hatte das Skript Probleme beim
Laden von Webseiten, beim Erkennen von Tags oder beim Schreiben von Dateien. Fehler in den
registrierten Webseiten werden hier aufgeführt - also nach jedem Eintragen einer URL und
nach jeder Änderung an seinen Webseiten hier genau schauen, ob das Skript auch alle
Einträge wie gewünscht erkannt hat! Im Falle eines Fehlers: weiter
unten gibt's eine Liste mit typischen Fehlern und wie man sie behebt.

Anschließend kann man die Publikationsseiten durchblättern und
das Resultat bewundern. Aber ACHTUNG: der
Web-Browser hält u.U. veraltete Kopien dieser Seiten und bemerkt nicht, daß die Seiten
mittlerweile neu generiert wurden. Im Zweifelsfall also ein Reload forcieren (mit
gedrückter Shift-Taste auf den Reload-Button des Browsers klicken). |
Die Tags, mit denen die zu registrierenden Webseiten aufbereitet werden müssen,
entsprechen dem HTML-Format. Da sie keine offiziellen HTML-Tags im Sinne der
HTML-Spezifikation sind, werden sie von jedem Web-Browser überlesen (als ob sich nicht
existent wären). Eine mit diesen Tags aufbereitete Seite sieht mit einem Web-Browser
betrachtet also genauso aus wie vor der Aufbereitung.
Folgende Tags stehen derzeit zur Verfügung:
Tag
|
Bedeutung, Hinweise, Beispiele etc.
|
| <SFBPUB> |
Markiert einen
Literatureintrag. |
|
Attribute: |
YEAR (Pflicht), TYPE (optional) |
|
Beispiele: |
<SFBPUB YEAR=1999> ...
</SFBPUB>
<SFBPUB YEAR=1992 TYPE=SFBTR-03> ... </SFBPUB> |
|
Die Jahresangabe ist Pflicht,
sie muß vierstellig und ohne Anführungsstriche erfolgen. Die Jahreszahl darf sich im
Bereich 1990 <= x <= (aktuelles Jahr+1) bewegen. Die Typ-Angabe ist optional und
unterscheidet verschiedene Arten von Veröffentlichungen (Konferenzbeitrag, Technischer
Bericht, Buch etc.). Die erlaubten Werte werden weiter unten
aufgeführt. Fehlt die Typ-Angabe, so wird von einem Konferenzbeitrag ausgegangen. |
| <SFBTITLE> |
Markiert innerhalb eines
Literatureintrags den Titel. |
|
Attribute: |
keine |
|
Beispiel: |
<SFBTITLE> ... </SFBTITLE> |
| <SFBAUTHORS> |
Markiert innerhalb eines
Literatureintrags die Autorenliste |
|
Attribute: |
keine |
|
Beispiel: |
<SFBAUTHORS> ...
</SFBAUTHORS> |
| <SFBREFERENCE> |
Markiert innerhalb eines
Literatureintrags eine Referenzangabe |
|
Attribute: |
keine |
|
Beispiel: |
<SFBREFERENCE> ...
</SFBREFERENCE> |
|
Die Referenzangabe ist zur
Aufnahme aller zusätzlichen Informationen wie Name der Konferenz, evtl. Hyperlink auf die
Konferenzseite, Konferenzort, Verlag der Proceedings, Seitenangaben, Ortsangaben etc.
gedacht. |
| <SFBURL> |
Markiert innerhalb eines
Literatureintrags einen Hyperlink zum Download der Veröffentlichung |
|
Attribute: |
keine |
|
Beispiel: |
<SFBURL><A
HREF=...>...</A></SFBURL> |
|
Typischerweise sollte der
Text zwischen öffnendem und schließendem Tag einen Hyperlink der Form <A HREF=...>
... </A> enthalten - was aber nicht zwingend ist. Das Generierungsskript fügt aber
auch keinen HTML-Hyperlink ein, sondern übernimmt nur evtl. existierende - d.h., wenn man
einen Download-Hyperlink angeben möchte, muß man selbst für das <A
HREF=...>...</A> sorgen! |
| <SFBABSTRACT> |
Markiert innerhalb eines
Literatureintrags dessen Abstract |
|
Attribute: |
keine |
|
Beispiel: |
<SFBABSTRACT>...</SFBABSTRACT> |
|
|
Bedeutung
|
| SFBTR-xx |
Technischer Bericht des SFB mit der Kennummer xx. Die Kennummer
bezieht sich auf das mit YEAR spezifizierte Jahr und muß zweistellig (ggf. mit führender
Null) sein. |
| TR |
Anderer (z.B. AG-interner) Technischer Bericht |
| INTERNAL |
Internes Dokument (Projekt- / Diplomarbeit) |
| DISS |
Dissertation |
| WORKSHOP |
Workshop-Beitrag |
| CONF |
Konferenzbeitrag |
| JOURNAL |
Journal-Beitrag |
| BOOKARTICLE |
Buchbeitrag |
| BOOK |
Buch |
| MONOGRAPH |
Monographie |
Weitere Hinweise:
- Groß- und Kleinschreibung wird bei den Tags nicht unterschieden, man kann also auch
alles klein schreiben, wenn man will.
- Jedes Tag muß vollständig auf einer Zeile stehen (d.h., kein Zeilenumbruch zwischen
< und >). Zwischen öffnendem und schließendem Tag dürfen aber natürlich
Zeilenumbrüche, Tabs etc. vorkommen.
- Tag-Attribute dürfen nicht in Anführungszeichen gesetzt werden und dürfen keine
Whitespaces enthalten (Leerzeichen, Tabs, Zeilenumbrüche etc.).
- Jeder Literatureintrag (der auf den SFB-Server übernommen werden soll), muß mit einem
<SFBPUB>-Tag eingeleitet werden.
- Alle anderen Tags dürfen nur innerhalb von <SFBPUB> ... </SFBPUB>
auftreten.
- Schließende Tags sind optional. Werden sie weggelassen, so wird der gesamte Text bis
zum nächsten öffnenden <SFBxxx>-Tag übernommen.
- Aus dem übernommenen Text werden sämtliche HTML-Formatierungen entfernt; insbesondere
Spielen damit auch Fett- und Kursivstellungen, Bilder, Paragraphen, Zeilenumbrüche etc.
keine Rolle.
- Das einzige, was neben reinem Text übernommen wird, sind Hyperlinks. Relative Links
werden dabei durch das Generierungsskript automatisch in entsprechende absolute Links
umgewandelt (da die relative Adressierung auf dem SFB-Server natürlich nicht mehr stimmen
würde). Achtung: Eine entsprechende Umwandlung wird bei allen URLs vorgenommen, die nicht
mit http: oder ftp: beginnen (jeweils Groß-/Kleinschreibungstolerant).
Dieses Generierungssystem ist natürlich nie richtig fertig. Es gibt daher (wie immer
:-) ein paar Beschränkungen, was seine Funktionalität angeht:
- Ein evtl. angegebener Abstract eines Literatureintrags wird derzeit noch nicht
verarbeitet. Zwar wird im Falle einer Abstract-Angabe in den generierten Literaturlisten
ein entsprechender Link auf eine Abstract-Seite angelegt, nur führt dieser derzeit noch
in die Leere...
- Bereits angedacht ist eine Kopplung mit der Erfahrungsdatenbank, die über ein
entsprechendes Web-Interface dann eine komfortable Suche nach Literatureinträgen
ermöglichen wird.
Hier eine Liste der Fehler, die das Generierungsskript erkennt:
Fehlermeldung
|
Ursache / Behebung
|
| couldn't connect to url |
Die als <url>
registrierte Literaturseite konnte nicht geladen werden. Das kann daran liegen, daß die url
fehlerhaft ist (die registrierten URLs überprüfen) oder der entsprechende Web-Server
nicht läuft oder über das Netz nicht erreichbar ist. |
| connection failed reading
line xx |
Die Netzverbindung zu dem
AG-Webserver brach beim Lesen der Zeile xx ab. Vermutlich auf Netzwerkprobleme
oder evtl. auch auf eine (grundlegend!) fehlerhafte HTML-Seite zurückzuführen. |
| nested
<SFBPUB> tag in line xx |
In der Zeile xx
tritt ein <SFBPUB>-Tag innerhalb eines anderen auf. Dieses und der folgende Text
werden bis zum nächsten korrekten Tag ignoriert. |
| incomplete SFBPUB tag at line
xx |
In Zeile xx tritt
ein <SFBPUB>-Tag ohne die erforderliche Jahresangabe auf. Kann auch an einem
Syntaxfehler innerhalb des <SFBPUB>-Tags liegen (dann werden die Attribute nicht
korrekt erkannt). |
| SFBPUB tag without a year
attribute in line xx |
In Zeile xx tritt
ein <SFBPUB>-Tag ohne die erforderliche Jahresangabe auf. |
| year attribute out of bounds
in line xx |
In Zeile xx ist die
Jahresangabe < 1990 oder > (aktuelles Jahr+1) |
| invalid URL in <SFBURL>
tag at line xx |
Der in Zeile xx in
dem <SFBURL>-Tag enthaltene Hyperlink (der Form <A HREF...> ... </A>)
konnte nicht korrekt erkannt werden. |
| couldn't open file
for writing |
Die Ausgabedatei file
konnte nicht geöffnet werden - ein Server Konfigurationsproblem; bitte bei wwwsfb501@informatik.uni-kl.de melden. |
2000-01-14
SFB 501 - Development of Large Systems with Generic Methods